英伟达GTC 2026大会は単なる製品発表の場にとどまらず、サプライチェーンの構造再編を促す重要なイベントとなった。英伟达の次世代AIプラットフォーム「Vera Rubin」のアーキテクチャの詳細が次第に明らかになる中、サムスン、マイクロン、インテルの三大チップ企業が果たす役割も浮き彫りになってきている。TrendForceの報告によると、最も注目されるサプライチェーンの動きの中で、英伟达のCEO黄仁勋は初めて、**子会社のGroq 3 LPUがサムスンの代工によって製造されることを正式に認めた**。また、マイクロンはHBM4が2026年第1四半期に量産段階に入ったと発表し、これまでVera Rubinのサプライチェーンから除外されていたとの噂を打ち消した。これらの情報は、HBM市場の競争構図とサプライヤーの交渉力に直接影響を与えている。**同時に、英インテルも本大会で英伟达との協力関係を正式に認め、Xeon 6プロセッサがDGX Rubin NVL8システムの計算能力を支えることが明らかになった。さらに長期的には、Wccftechの報道によると、英インテルは2028年に登場予定の次世代Feynman GPUのパッケージング生産において、ファウンドリーとしての役割を果たす可能性も示唆されている。**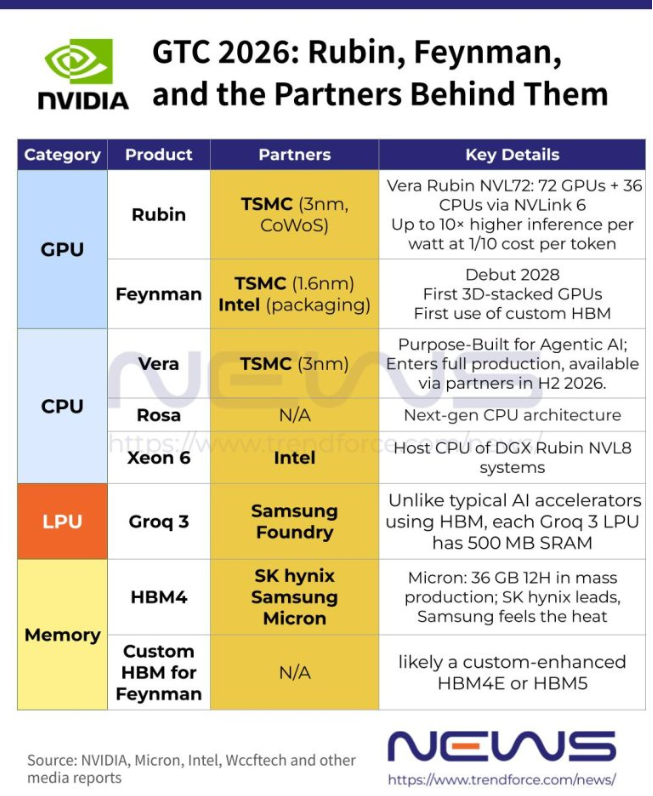サムスン、LPU代工受注を獲得、黄仁勋が自ら確認-------------------Groq 3は本大会で最も注目された発表の一つだ。**高速推論に特化したこのLPUはVera Rubinプラットフォームに統合され、2026年後半から出荷開始予定だ。**韓国の朝鮮日報によると、黄仁勋は大会で初めて、Groq 3の製造をサムスンのウエハー代工工場が担当すると正式に認めた。これは、英伟达が昨年200億ドルでGroqを買収する以前から、Groqとサムスンの間に既に代工契約が存在していたことを示している。技術面では、Groq 3の設計思想は主流のAIアクセラレータと大きく異なる。Tom's Hardwareの報告によると、各Groq 3 LPUには500MBのSRAMが内蔵されており、これは通常CPUやGPUのキャッシュに使われる超高速メモリだ。この容量はRubin GPUに搭載される288GBのHBM4には及ばないが、帯域幅は約150TB/sに達し、HBM4の22TB/sを大きく上回る。帯域幅を重視したAI推論やデコード処理において、この設計は推論性能の大幅な向上に寄与すると期待されている。**サムスンがこの代工契約を獲得したことは、英伟达のサプライチェーンにおける役割がHBM4メモリ供給から論理チップの代工へと拡大し、Vera Rubinプラットフォームにおける戦略的地位が強化されたことを意味する。**マイクロン、HBM4の量産開始、SKハイニックスの独占プレミアムに圧力----------------------マイクロンは本大会で正式に、36GB 12層スタックのHBM4が2026年第1四半期から英伟达Vera Rubinプラットフォーム向けに量産供給を開始したと発表した。この製品はピンレートが11Gb/s超、帯域幅は2.8TB/s超で、HBM3Eと比較して2.3倍の性能向上と、消費電力効率も20%以上改善している。さらに、マイクロンは48GB 16層スタックのHBM4サンプルも顧客に送付開始しており、容量は12層版より33%増加している。この進展の市場への意義は、マイクロンの技術突破だけにとどまらない。Joseilbo.comの分析によると、マイクロンの量産加速はHBM供給の集中度を低下させ、出荷量配分や価格交渉において既存の供給業者に対してより大きな圧力をかけるとされる。報道は、「この動きの核心的な影響は、直接的にSKハイニックスの市場シェアを奪うことではなく、HBM需要のピーク時に形成された寡占的なプレミアムを弱めることにある」と指摘している。一方、サムスンもより直接的な競争圧力に直面している。Joseilbo.comは、サムスンが技術力を示すために正式にHBM4の生産を推進している一方で、マイクロンが英伟达Vera Rubinプラットフォーム向けに大規模供給を行うことで、「量産可能か」から「実際の採用規模」へと業界の競争基準が変わる可能性があり、サムスンにとって新たな挑戦となると述べている。英インテル、二本立ての戦略を展開、Feynman封止合作が浮上-----------------------英インテルの存在感も本大会で非常に大きい。英インテルは正式に、そのXeon 6プロセッサが英伟达のDGX Rubin NVL8システムの計算能力を支えることを確認した。Tom's Hardwareの報告によると、この製品は前世代と比べてメモリ帯域幅が2.3倍に向上し、次世代GPUのAIワークロードに対してスケーラブルな高性能計算能力を提供する。長期的な展望として、Wccftechは、英伟达が英インテルと晶圆代工分野で協力し、英インテルのEMIBを含む先進封止技術を活用して、2028年に登場予定のFeynman GPUの封止を支援する可能性に言及している。なお、Feynman GPUのチップ本体はTSMCの1.6nmプロセスで製造される見込みであり、英インテルの関与は主に封止段階に集中すると考えられる。Feynmanプラットフォームはまた、3Dチップスタッキング技術も導入される見込みで、これは英伟达のGPU製品で初めて採用される可能性がある。ストレージ面では、英伟达は標準規格の次世代HBMではなく、カスタムHBMをFeynmanに搭載し、AIデータセンター向けプラットフォームの差別化競争力をさらに高める計画だ。リスク提示及び免責事項市場にはリスクが伴います。投資は自己責任で行ってください。本稿は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではありません。読者は本記事の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己にあります。
サムスン、マイクロン、インテルがNvidiaの大口受注を分け合う:サムスンはLPUを受託製造し、マイクロンはHBM4を量産
英伟达GTC 2026大会は単なる製品発表の場にとどまらず、サプライチェーンの構造再編を促す重要なイベントとなった。英伟达の次世代AIプラットフォーム「Vera Rubin」のアーキテクチャの詳細が次第に明らかになる中、サムスン、マイクロン、インテルの三大チップ企業が果たす役割も浮き彫りになってきている。
TrendForceの報告によると、最も注目されるサプライチェーンの動きの中で、英伟达のCEO黄仁勋は初めて、子会社のGroq 3 LPUがサムスンの代工によって製造されることを正式に認めた。また、マイクロンはHBM4が2026年第1四半期に量産段階に入ったと発表し、これまでVera Rubinのサプライチェーンから除外されていたとの噂を打ち消した。これらの情報は、HBM市場の競争構図とサプライヤーの交渉力に直接影響を与えている。
同時に、英インテルも本大会で英伟达との協力関係を正式に認め、Xeon 6プロセッサがDGX Rubin NVL8システムの計算能力を支えることが明らかになった。さらに長期的には、Wccftechの報道によると、英インテルは2028年に登場予定の次世代Feynman GPUのパッケージング生産において、ファウンドリーとしての役割を果たす可能性も示唆されている。
サムスン、LPU代工受注を獲得、黄仁勋が自ら確認
Groq 3は本大会で最も注目された発表の一つだ。**高速推論に特化したこのLPUはVera Rubinプラットフォームに統合され、2026年後半から出荷開始予定だ。**韓国の朝鮮日報によると、黄仁勋は大会で初めて、Groq 3の製造をサムスンのウエハー代工工場が担当すると正式に認めた。これは、英伟达が昨年200億ドルでGroqを買収する以前から、Groqとサムスンの間に既に代工契約が存在していたことを示している。
技術面では、Groq 3の設計思想は主流のAIアクセラレータと大きく異なる。Tom’s Hardwareの報告によると、各Groq 3 LPUには500MBのSRAMが内蔵されており、これは通常CPUやGPUのキャッシュに使われる超高速メモリだ。
この容量はRubin GPUに搭載される288GBのHBM4には及ばないが、帯域幅は約150TB/sに達し、HBM4の22TB/sを大きく上回る。帯域幅を重視したAI推論やデコード処理において、この設計は推論性能の大幅な向上に寄与すると期待されている。
サムスンがこの代工契約を獲得したことは、英伟达のサプライチェーンにおける役割がHBM4メモリ供給から論理チップの代工へと拡大し、Vera Rubinプラットフォームにおける戦略的地位が強化されたことを意味する。
マイクロン、HBM4の量産開始、SKハイニックスの独占プレミアムに圧力
マイクロンは本大会で正式に、36GB 12層スタックのHBM4が2026年第1四半期から英伟达Vera Rubinプラットフォーム向けに量産供給を開始したと発表した。この製品はピンレートが11Gb/s超、帯域幅は2.8TB/s超で、HBM3Eと比較して2.3倍の性能向上と、消費電力効率も20%以上改善している。さらに、マイクロンは48GB 16層スタックのHBM4サンプルも顧客に送付開始しており、容量は12層版より33%増加している。
この進展の市場への意義は、マイクロンの技術突破だけにとどまらない。Joseilbo.comの分析によると、マイクロンの量産加速はHBM供給の集中度を低下させ、出荷量配分や価格交渉において既存の供給業者に対してより大きな圧力をかけるとされる。報道は、「この動きの核心的な影響は、直接的にSKハイニックスの市場シェアを奪うことではなく、HBM需要のピーク時に形成された寡占的なプレミアムを弱めることにある」と指摘している。
一方、サムスンもより直接的な競争圧力に直面している。Joseilbo.comは、サムスンが技術力を示すために正式にHBM4の生産を推進している一方で、マイクロンが英伟达Vera Rubinプラットフォーム向けに大規模供給を行うことで、「量産可能か」から「実際の採用規模」へと業界の競争基準が変わる可能性があり、サムスンにとって新たな挑戦となると述べている。
英インテル、二本立ての戦略を展開、Feynman封止合作が浮上
英インテルの存在感も本大会で非常に大きい。英インテルは正式に、そのXeon 6プロセッサが英伟达のDGX Rubin NVL8システムの計算能力を支えることを確認した。Tom’s Hardwareの報告によると、この製品は前世代と比べてメモリ帯域幅が2.3倍に向上し、次世代GPUのAIワークロードに対してスケーラブルな高性能計算能力を提供する。
長期的な展望として、Wccftechは、英伟达が英インテルと晶圆代工分野で協力し、英インテルのEMIBを含む先進封止技術を活用して、2028年に登場予定のFeynman GPUの封止を支援する可能性に言及している。なお、Feynman GPUのチップ本体はTSMCの1.6nmプロセスで製造される見込みであり、英インテルの関与は主に封止段階に集中すると考えられる。
Feynmanプラットフォームはまた、3Dチップスタッキング技術も導入される見込みで、これは英伟达のGPU製品で初めて採用される可能性がある。ストレージ面では、英伟达は標準規格の次世代HBMではなく、カスタムHBMをFeynmanに搭載し、AIデータセンター向けプラットフォームの差別化競争力をさらに高める計画だ。
リスク提示及び免責事項
市場にはリスクが伴います。投資は自己責任で行ってください。本稿は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではありません。読者は本記事の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己にあります。